openai視頻生成模型sora爆火 OpenAI王炸模型官方技術報告解讀
openai視頻生成模型sora最近徹底爆火瞭,對於這次的爆火事件很多人還不是很瞭解,想要知道OpenAI王炸模型究竟是什麼樣的,那麼大傢可以看看下面KALA遊戲小編帶來的官方技術報告解讀,會給大傢具體的介紹這次科技大爆炸的詳情。
OpenAI王炸模型官方技術報告解讀
OpenAI2月16日凌晨發佈瞭文生視頻大模型Sora,在科技圈引起一連串的震驚和感嘆,在2023年,我們見證瞭文生文、文生圖的進展速度,視頻可以說是人類被AI攻占最慢的一塊“處女地”。而在2024年開年,OpenAI就發佈瞭王炸文生視頻大模型Sora,它能夠僅僅根據提示詞,生成60s的連貫視頻,“碾壓”瞭行業目前大概隻有平均“4s”的視頻生成長度。


為瞭方便理解,我們簡單總結瞭這個模型的強大之處:
1、文本到視頻生成能力:Sora能夠根據用戶提供的文本描述生成長達60S的視頻,這些視頻不僅保持瞭視覺品質,而且完整準確還原瞭用戶的提示語。
2、復雜場景和角色生成能力:Sora能夠生成包含多個角色、特定運動類型以及主題精確、背景細節復雜的場景。它能夠創造出生動的角色表情和復雜的運鏡,使得生成的視頻具有高度的逼真性和敘事效果。
3、語言理解能力:Sora擁有深入的語言理解能力,能夠準確解釋提示並生成能表達豐富情感的角色。這使得模型能夠更好地理解用戶的文本指令,並在生成的視頻內容中忠實地反映這些指令。
4、多鏡頭生成能力:Sora可以在單個生成的視頻中創建多個鏡頭,同時保持角色和視覺風格的一致性。這種能力對於制作電影預告片、動畫或其他需要多視角展示的內容非常有用。
5、從靜態圖像生成視頻能力:Sora不僅能夠從文本生成視頻,還能夠從現有的靜態圖像開始,準確地動畫化圖像內容,或者擴展現有視頻,填補視頻中的缺失幀。
6、物理世界模擬能力:Sora展示瞭人工智能在理解真實世界場景並與之互動的能力,這是朝著實現通用人工智能(AGI)的重要一步。它能夠模擬真實物理世界的運動,如物體的移動和相互作用。
可以說,Sora的出現,預示著一個全新的視覺敘事時代的到來,它能夠將人們的想象力轉化為生動的動態畫面,將文字的魔力轉化為視覺的盛宴。在這個由數據和算法編織的未來,Sora正以其獨特的方式,重新定義著我們與數字世界的互動。
01
以下為OpenAI文生視頻模型Sora官方技術報告
我們探索瞭利用視頻數據對生成模型進行大規模訓練。具體來說,我們在不同持續時間、分辨率和縱橫比的視頻和圖像上聯合訓練瞭以文本為輸入條件的擴散模型。我們引入瞭一種transformer架構,該架構對視頻的時空序列包和圖像潛在編碼進行操作。我們最頂尖的模型Sora已經能夠生成最長一分鐘的高保真視頻,這標志著我們在視頻生成領域取得瞭重大突破。我們的研究結果表明,通過擴大視頻生成模型的規模,我們有望構建出能夠模擬物理世界的通用模擬器,這無疑是一條極具前景的發展道路。
這份技術報告主要聚焦於兩大方面:首先,我們詳細介紹瞭一種將各類可視數據轉化為統一表示的方法,從而實現瞭對生成式模型的大規模訓練;其次,我們對Sora的能力及其局限性進行瞭深入的定性評估。需要註意的是,本報告並未涉及模型的具體技術細節。
在過去的研究中,許多團隊已經嘗試使用遞歸網絡、生成對抗網絡、自回歸Transformer和擴散模型等各種方法,對視頻數據的生成式建模進行瞭深入研究。然而,這些工作通常僅限於較窄類別的視覺數據、較短的視頻或固定大小的視頻上。相比之下,Sora作為一款通用的視覺數據模型,其卓越之處在於能夠生成跨越不同持續時間、縱橫比和分辨率的視頻和圖像,甚至包括生成長達一分鐘的高清視頻。
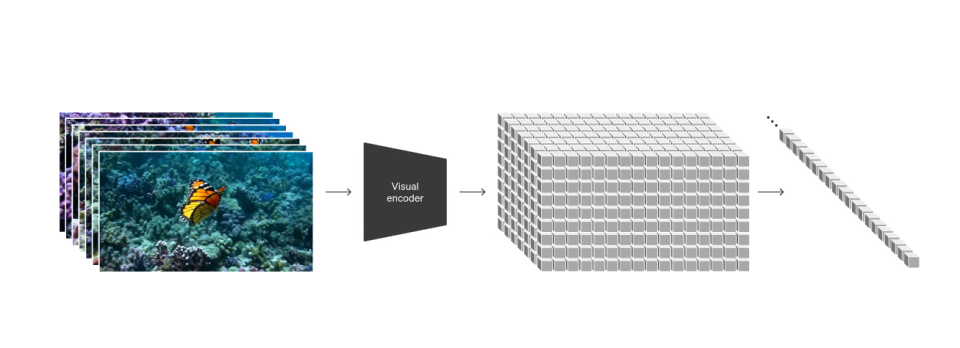
將可視數據轉換成數據包(patchs)
在可視數據的處理上,我們借鑒瞭大語言模型的成功經驗。這些模型通過對互聯網規模的數據進行訓練,獲得瞭強大的通用能力。同樣,我們考慮如何將這種優勢引入到可視數據的生成式模型中。大語言模型通過token將各種形式的文本代碼、數學和自然語言統一起來,而Sora則通過視覺包(patchs)實現瞭類似的效果。我們發現,對於不同類型的視頻和圖像,包是一種高度可擴展且有效的表示方式,對於訓練生成模型具有重要意義。
圖註:OpenAI專門設計的解碼器模型,它可以將生成的潛在表示重新映射回像素空間
在更高層次上,我們首先將視頻壓縮到一個低維度的潛在空間:這是通過對視頻進行時間和空間上的壓縮實現的。這個潛在空間可以看作是一個“時空包”的集合,從而將原始視頻轉化為這些包。
視頻壓縮網絡
我們專門訓練瞭一個網絡,專門負責降低視覺數據的維度。這個網絡接收原始視頻作為輸入,並輸出經過壓縮的潛在表示。Sora模型就是在這個壓縮後的潛在空間中接受訓練,並最終生成視頻。此外,我們還設計瞭一個解碼器模型,它可以將生成的潛在表示重新映射回像素空間,從而生成可視的視頻或圖像。
時空包
當給定一個壓縮後的輸入視頻時,我們會從中提取出一系列的時空包,這些包被用作轉換token。這一方案不僅適用於視頻,因為視頻本質上就是由連續幀構成的,所以圖像也可以看作是單幀的視頻。通過這種基於包的表示方式,Sora能夠跨越不同分辨率、持續時間和縱橫比的視頻和圖像進行訓練。在推理階段,我們隻需在適當大小的網格中安排隨機初始化的包,就可以控制生成視頻的大小和分辨率。
用於視頻生成的縮放Transformers
Sora是一個擴散模型,它接受輸入的噪聲包(以及如文本提示等條件性輸入信息),然後被訓練去預測原始的“幹凈”包。重要的是,Sora是一個基於擴散的轉換器模型,這種模型已經在多個領域展現瞭顯著的擴展性,包括語言建模、計算機視覺以及圖像生成等領域。

圖註:隨著訓練量的增加,擴散轉換器生成的樣本質量有瞭明顯提高
在這項工作中,我們發現擴散轉換器在視頻生成領域同樣具有巨大的潛力。我們展示瞭不同訓練階段下,使用相同種子和輸入的視頻樣本對比,結果證明瞭隨著訓練量的增加,樣本質量有著明顯的提高。
豐富的持續時間、分辨率與縱橫比
過去,圖像和視頻生成方法常常需要將視頻調整大小、裁剪或修剪至標準尺寸,如4秒、256x256分辨率的視頻。但Sora打破瞭這一常規,它直接在原始大小的數據上進行訓練,從而帶來瞭諸多優勢。
采樣更靈活
Sora具備出色的采樣能力,無論是寬屏1920x1080p視頻、垂直1080x1920視頻,還是介於兩者之間的任何視頻尺寸,它都能輕松應對。這意味著Sora可以為各種設備生成與其原始縱橫比完美匹配的內容。更令人驚嘆的是,即使在生成全分辨率內容之前,Sora也能以較小的尺寸迅速創建內容原型。而所有這一切,都得益於使用相同的模型。

圖註:Sora可以為各種設備生成與其原始縱橫比完美匹配的內容
改進構圖與框架
我們的實驗結果顯示,在視頻的原始縱橫比上進行訓練,能夠顯著提升構圖和框架的質量。為瞭驗證這一點,我們將Sora與一個將所有訓練視頻裁剪為方形的模型版本進行瞭比較。結果發現,在正方形裁剪上訓練的模型有時會生成僅部分顯示主題的視頻。而Sora則能呈現出更加完美的幀,充分展現瞭其在視頻生成領域的卓越性能。

圖註:將所有訓練視頻裁剪為方形的模型相比(左),Sora能呈現出更加完美的幀
語言理解深化
為瞭訓練文本轉視頻生成系統,需要大量帶有相應文本字幕的視頻。為此,我們借鑒瞭DALL·E3中的re-captioning技術,並應用於視頻領域。首先,我們訓練瞭一個高度描述性的轉譯員模型,然後使用它為我們訓練集中的所有視頻生成文本轉譯。通過這種方式,我們發現對高度描述性的視頻轉譯進行訓練,可以顯著提高文本保真度和視頻的整體質量。
與此同時,與DALL·E3類似,我們還利用GPT技術將簡短的用戶提示轉換為更長的詳細轉譯,並將其發送到視頻模型。這一創新使得Sora能夠精確地按照用戶提示生成高質量的視頻。
圖片與視頻提示
在上述所有結果和我們的演示中,你可能已經註意到瞭文本轉視頻的示例。但Sora的功能遠不止於此,它還能接受其他類型的輸入提示,如預先存在的圖像或視頻。這種多樣化的提示方式使Sora能夠執行廣泛的圖像和視頻編輯任務,如創建完美的循環視頻、將靜態圖像轉化為動畫、向前或向後擴展視頻等。
將DALL·E圖片變成動畫
值得一提的是,Sora還能在提供圖像和提示作為輸入的情況下生成視頻。下面展示的示例視頻就是基於DALL·E 2和DALL·E3的圖像生成的。這些示例不僅證明瞭Sora的強大功能,還展示瞭它在圖像和視頻編輯領域的無限潛力。


一幅逼真的雲朵圖像生成視頻,上面寫著“SORA”;在一個華麗的歷史大廳裡,一股巨大的浪潮達到頂峰,並開始崩散,兩個沖浪者抓住時機,巧妙地在海浪表面飛馳
擴展生成視頻
Sora不僅具備生成視頻的能力,更能在時間維度上實現向前或向後的無限擴展。以下三個視頻便是從同一生成視頻片段出發,逐步向後擴展的示例。盡管它們的起始部分各異,但結局卻出奇地一致。
視頻到視頻編輯
隨著擴散模型的發展,我們已經開發出多種方法來編輯基於文本提示的圖像和視頻。在此,我們將其中一種名為SDEdit32的技術應用於Sora。這項技術賦予瞭Sora轉換零拍攝輸入視頻風格和環境的能力,為視頻編輯領域帶來瞭革命性的變革。
視頻的無縫連接
更令人驚嘆的是,Sora還能在兩個截然不同的輸入視頻之間實現無縫過渡。通過逐漸插入技術,我們能夠在具有完全不同主題和場景構圖的視頻之間創建出流暢自然的過渡效果。
圖片生成能力
Sora的出色能力不止於數據處理和分析,它現在還能生成圖像!這一創新功能的實現得益於一種獨特的算法,該算法在一個精確的時間范圍內,巧妙地在空間網格中排列高斯噪聲補丁。
值得一提的是,Sora的圖像生成功能不僅限於特定大小的圖像。它可以根據用戶需求,生成可變大小的圖像,最高可達驚人的2048 × 2048分辨率。

圖註:一個女人在秋天的特寫肖像,每一個細節都被捕捉得淋漓盡致,淺景深的應用使得主體脫穎而出

圖註:充滿生機的珊瑚礁吸引瞭五顏六色的魚類和海洋生物
新的模擬能力
在大規模訓練過程中,我們發現視頻模型展現出瞭許多令人興奮的新能力。這些功能使得Sora能夠模擬現實世界中的人物、動物和環境等某些方面。值得註意的是,這些屬性的出現並沒有依賴於任何明確的3D建模、物體識別等歸納偏差,而是純粹通過模型的尺度擴展而自然湧現的。
3D一致性:在3D一致性方面,Sora能夠生成帶有動態攝像頭運動的視頻。隨著攝像頭的移動和旋轉,人物和場景元素在三維空間中始終保持一致的運動規律。
較長視頻的連貫性和對象持久性:視頻生成領域面對的一個重要挑戰就是,在生成的較長視頻中保持時空連貫性和一致性。Sora,雖然不總是,但經常能夠有效地為短期和長期物體間的依賴關系建模。例如,在生成的視頻中,人物、動物和物體即使在被遮擋或離開畫面後,仍能被準確地保存和呈現。同樣地,Sora能夠在單個樣本中生成同一角色的多個鏡頭,並在整個視頻中保持其外觀的一致性。
與世界互動:Sora有時還能以簡單的方式模擬影響世界狀態的行為。例如,畫傢可以在畫佈上留下新的筆觸。隨著時間的推移,一個人吃漢堡時也能在上面留下咬痕。
模擬數字世界:Sora還能夠模擬人工過程,比如視頻遊戲。它可以在高保真度渲染世界及其動態的同時,用基本策略控制《我的世界》中的玩傢。這些功能都無需額外的訓練數據或調整模型參數,隻需向Sora提示“我的世界”即可實現。
這些新能力表明,視頻模型的持續擴展為開發高性能的物理和數字世界模擬器提供瞭一條充滿希望的道路。通過模擬生活在這些世界中的物體、動物和人等實體,我們可以更深入地理解現實世界的運行規律,並開發出更加逼真、自然的視頻生成技術。
局限性與展望
盡管Sora在模擬能力方面已經取得瞭顯著的進展,但它目前仍然存在許多局限性。例如,它不能準確地模擬許多基本相互作用的物理過程,如玻璃破碎等。此外,在某些交互場景中,比如吃東西時,Sora並不能總是產生正確的對象狀態變化。我們在發佈頁面中列舉瞭模型的其他常見故障模式,包括在長時間樣本中發展的不一致性或某些對象不受控的出現等。
然而,我們相信隨著技術的不斷進步和創新,Sora所展現出的能力預示著視頻模型持續擴展的巨大潛力。未來,我們期待看到更加先進的視頻生成技術,能夠更準確地模擬現實世界中的各種現象和行為,並為我們帶來更加逼真、自然的視覺體驗。
02
圈內人如何看Sora?
最後再來看看各位技術大牛和內容行業從業者如何評價Sora?
馬斯克評OpenAI視頻模型:人類認賭服輸,但AI增強的人類將創造出最好作品
OpenAI周四發佈瞭首個視頻生成模型Sora。馬斯克的前女友格萊姆斯發佈瞭一連串帖子,討論這項新技術對電影以及更廣泛的藝術創作的影響。
馬斯克在其中一條帖子下回應稱:“AI增強的人類將在未來幾年裡創造出最好的作品。”
值得註意的是,馬斯克和格萊姆斯在過去大約半年時間裡一直在就他們三個子女的撫養權問題對薄公堂。兩人之間在X平臺上這次罕見的互動引發瞭人們對他們目前關系狀態的猜測。
稍早,一位X用戶分享瞭Sora生成的一名女子在東京街頭漫步的視頻,並評論稱:“OpenAI今天宣佈瞭Sora,它使用混合擴散和變壓器模型架構生成長達1分鐘的視頻。他們似乎又領先瞭其他所有人1-2年。”另一位X用戶評論稱:“gg皮克斯。”
馬斯克回應稱:“gg人類。”(註:gg是網絡遊戲用語“goodgames”的縮寫,主要用於遊戲結束後,輸贏雙方都可以用,但現在多由失敗方發出,表示認賭服輸、心服口服的意思。)在馬斯克帖子的評論區裡,還有用戶附和道:“gg好萊塢”。
Jim Fan感嘆:Sora是一個數據驅動的物理引擎
英偉達人工智能研究院Jim Fan表示“如果你還是把Sora當做DALLE那樣的生成式玩具,還是好好想想吧,這是一個數據驅動的物理引擎。”JimFan大神的言下之意是,我們不能忽略Sora背後,“世界模型”更進一步,AI已經可以讀懂物理規律。
YouTube大V :動畫師和3D藝術傢的工作可能有危險瞭
YouTube大V PaddyGalloway感慨:“內容創作永遠改變瞭。這不是誇張。我在YouTube世界已經15年瞭,OpenAI剛剛展示的東西讓我說不出話來…”他認為,Sora將帶來以下這些改變:
● 動畫師和3D藝術傢的工作可能有危險瞭庫存素材網站將變得無關緊要
● 任何人都可以立即擁有出色的B-roll(輔助鏡頭)
● 制作精美視頻的門檻降至零
● 在一個每個人都能制作出美麗視頻的世界裡,內容背後的“想法”和故事變得更加重要
● Sora將真正顛覆教育、視頻論文和解說視頻的細分市場
AI創業公司創始人:五年之後,你將能夠生成完全沉浸式的世界,並實時體驗它們
Takeoff AI是專註於AITools的創業公司,它的創始人認為這一波OpenAI新技術的最大受益者可能是虛擬現實。“在兩周內,我們連續有瞭蘋果的VisionPro和OpenAI的Sora文本到視頻AI模型。五年之後,你將能夠生成完全沉浸式的世界,並實時體驗它們。Holodeck(應該是指今年火爆的掌機Steamdeck的虛擬現實版本)很快就要來瞭。”
除瞭這些技術上的猜測和對產業影響的正面預測外,也有老反對派指出Sora的潛在問題不那麼容易糾正。
Gary Marcus:Sora奇怪的物理故障可能不是數據中出現的
紐約大學教授GaryMarcus以其對AI領域的深刻見解和對現有技術的批判性思考而聞名,他的觀點和研究對AI社區產生瞭重要影響。他表示“Sora奇怪的物理故障(例如動物和人在人群中自發出現和消失)令人著迷:這些錯誤可能不是數據中出現的。這種小故障在某些方面類似於LLM“幻覺”,即從有損壓縮中(大致)解壓縮產生的偽影,而不是來自這個世界的東西。”
而且這種錯誤在他看來是一種“與現實世界物理學的系統性偏差,可能很難糾正。”
不過此刻最悲傷的應該是Google,今天本來拿來翻盤用的的Gemini1.5發佈風頭完全被Sora壓過。作為AI界的汪峰,它對此沒有評論。
相關推薦
-
《女神異聞錄3 Reload》今日發售!Steam好評如潮
《女神異聞錄3》的重制作品《女神異聞錄3 Reload》今日正式發售,登陸PS4|5、XboxOne、XSX|S、PC(Steam)首發XGP。截止至本稿發出時《女神異聞錄3 Re...
-
《猛獸派對》提供神龍通行證 面向所有玩傢免費開放
《猛獸派對》官方宣佈,為喜迎龍年,將從北京時間2月8日中午12點開始,提供為16天的召喚神龍通行證,並面向所有玩傢免費開放。 玩傢可以通過遊玩以及完成每日神龍挑戰來提升召喚神龍通行...
-
《漫威蜘蛛俠2》新補丁加入New Game+ 3/7上線
Insomniac Games宣佈瞭其廣受歡迎的開放世界動作冒險遊戲《漫威蜘蛛俠2》的下一個大型更新補丁的推出日期。 這一更新原本計劃在2023年推出,後來被推遲到2024年初,將...
-
《二之國:交錯世界》定檔2月28日,童話冒險邀你啟程
唯美童話冒險手遊《二之國:交錯世界》將於2024年2月28日正式上線,踏入童話夢境,拯救古老王國!冒險傢,你準備好瞭嗎? 延續唯美畫風 大師手作天籟 作為由Level-5策劃、吉卜...
-
全世界都在說中國話!東南亞英文版《P3R》竟是中文
《女神異聞錄3:Reload(Persona 3 Reload)》已經發售一段時間瞭,但是有趣的是,在遊戲發售之初,東南亞地區玩傢訂購的實體版本遊戲封面上寫著“Engl...
-
《黃金樹幽影》比本體寧姆格福還要大 喬治馬丁未參與
宮崎英高告訴外媒Eurogamer,《黃金樹幽影》是該公司有史以來最大的DLC,他還透露瞭DLC的更多細節,並證實瞭《權力的遊戲》作者喬治·馬丁沒有參與提供新的內容。...
-
kun哥爆料2月上旬XGP陣容:生化3RE、NFL 24等
靠譜舅舅黨billbil-kun帶來瞭2月上旬的XGP陣容爆料,包含《速速上菜》、《生化危機3:重制版》和《Madden NFL 24》(EA Play),具體登陸日期未知。
-
《星之後裔2:吠陀騎士》新預告公佈!3.5開啟預註冊
今日,官方公佈瞭《星之後裔2:吠陀騎士(Astra: Knights of Veda)》新預告片,並宣佈遊戲將於3月5日開啟預註冊。 【遊俠網】《星之後裔2:吠陀騎士》新預告 該作...
-
PS5新銷售數據曝光 全球出貨量已達到5480萬臺
在第三季度,索尼全球出貨瞭820萬臺PS5,比上一財年第三季度增加瞭110萬臺。目前,本財年累計出貨量已達1640萬臺。索尼預計在本財年將創下2500萬臺的出貨量新紀錄,這意味著在...
-
命運方舟“點亮”拉斯維加斯巨蛋,全球玩傢狂歡
北京時間1月31日,騰訊遊戲代理發行的全球知名3A開放世界角色扮演遊戲《命運方舟》在美國拉斯維加斯Sphere場館霸屏4小時,展示瞭巨型春節祝福內容,在新春小年夜前夕為全球玩傢送上...